io_uring
Linux Kernel 5.1 版本开始加入一个重大 feature:io_uring
io_uring是一套全新的 syscall,一套全新的 async API,更高的性能,更好的兼容性,来迎接高 IOPS,高吞吐量的未来。
参照
在此之前Linux系统一直没有能与Windows IOCP对标的真正的异步IO。
过去基本都是基于select,pool,epool来模拟异步IO,实际它们只是IO的多路复用,也称事件驱动IO。
基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
| 方式 | 跨平台能力 | 效率 | IO数量 | 说明 |
|---|---|---|---|---|
| select | 好 | 一般 | 1024个IO(可扩展) | 水平触发 |
| pool | 一般 | 一般 | IO无上限 | 水平触发 |
| epool | 差 | 高 | IO无上限 | 水平(默认)/边缘触发 |
Level_triggered(水平触发): 当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据一次性全部读写完(如读写缓冲区太小), 那么下次调用 epoll_wait()时,它还会通知你在上没读写完的文件描述符上继续读写,当然如果你一直不去读写,它会一直通知你!!!如果系统中有大量你不需要读写的就绪文件描述符,而它们每次都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率!!!
Edge_triggered(边缘触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符!!!
libev,libuv,libaio 都是对异步模型的封闭,实际实现还是基于event driven IO。
| 库 | 异步DNS解析 | 线程支持 | IOCP |
|---|---|---|---|
| libev | 不支持 | 单线程 | 不支持 |
| libuv | 支持 | 多线程 | 支持 |
io_uring 技术特点
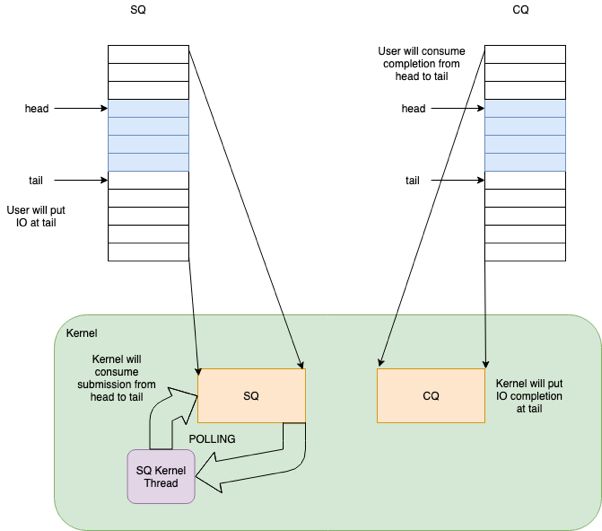
- 用户态和内核态共享提交队列(submission queue)和完成队列(completion queue)
- IO 提交和收割可以 offload 给 Kernel,且提交和完成不需要经过系统调用(system call)
- 支持 Block 层的 Polling(轮询) 模式
- 通过提前注册用户态内存地址,减少地址映射的开销
- 支持 buffered IO
io_uring
应用程序可以使用两个队列,Submission Queue(SQ) 和 Completion Queue(CQ) 来和 Kernel 进行通信。
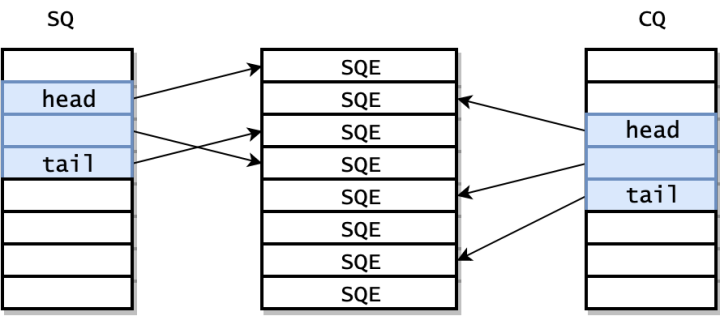
内核还提供了一个 Submission Queue Entries(SQEs)数组。
SQEs是为了方便通过 RingBuffer 提交内存上不连续的请求。SQ 和 CQ 中每个节点保存的都是 SQEs 数组的偏移量,而不是实际的请求,实际的请求只保存在 SQEs 数组中。这样在提交请求时,就可以批量提交一组 SQEs 上不连续的请求。
但由于 SQ,CQ,SQEs 是在内核中分配的,所以用户态程序并不能直接访问。io_setup 的返回值是一个 fd,应用程序使用这个 fd 进行 mmap,和 kernel 共享一块内存。
这块内存共分为三个区域,分别是 SQ,CQ,SQEs。kernel 返回的 io_sqring_offset 和 io_cqring_offset 分别描述了 SQ 和 CQ 的指针在 mmap 中的 offset。而 SQEs 则直接对应了 mmap 中的 SQEs 区域。
mmap 的时候需要传入 MAP_POPULATE 参数,以防止内存被 page fault。
Syscall API
/usr/src/kernels/5.10.5-1.el7.elrepo.x86_64/include/linux/syscalls.h
/usr/src/kernels/5.10.5-1.el7.elrepo.x86_64/include/trace/events/io_uring.h
| api | params | return | note |
|---|---|---|---|
| io_uring_setup | u32 entries, struct io_uring_params __user *p | long | 准备 |
| io_uring_register | unsigned int fd, unsigned int op, void __user *arg, unsigned int nr_args | long | 注册 |
| io_uring_enter | unsigned int fd, u32 to_submit, u32 min_complete, u32 flags, const sigset_t __user *sig, size_t sigsz | long | 提交 |
io_uring_setup
- u32 entries : 队列大小
- struct io_uring_params __user *p : io_uring参数 (flags、sq_thread_cpu、sq_thread_idle三个输入参数其它都是输出参数内核配置) io_uring_params.flags取值如下
#define IORING_SETUP_IOPOLL (1U << 0) /* io_context is polled */
#define IORING_SETUP_SQPOLL (1U << 1) /* SQ poll thread */
#define IORING_SETUP_SQ_AFF (1U << 2) /* sq_thread_cpu is valid */
#define IORING_SETUP_CQSIZE (1U << 3) /* app defines CQ size */
#define IORING_SETUP_CLAMP (1U << 4) /* clamp SQ/CQ ring sizes */
#define IORING_SETUP_ATTACH_WQ (1U << 5) /* attach to existing wq */
设置IORING_SETUP_SQPOLL 的 flag,这样内核会启动一个内核线程,即SQ线程。这个内核线程可以运行在某个指定的 core 上(通过 sq_thread_cpu 配置)。 这个内核线程会不停的 Poll SQ,除非在一段时间内没有 poll 到任何请求(通过 sq_thread_idle 配置),才会挂起,用户态程序只需要向IO提交队列中写入IO event即可。
设置了IORING_SETUP_IOPOLL,内核采用 polling 的模式收割完成IO。当没有使用 SQ 线程时,io_uring_enter 函数会主动的 poll,以检查提交的IO请求是否已经完成。
- return : ring_fd <0失败(-errno)
io_uring_register
- unsigned int fd : ring_fd
- unsigned int op : 参数,取值如下
#define IORING_REGISTER_BUFFERS 0
#define IORING_UNREGISTER_BUFFERS 1
#define IORING_REGISTER_FILES 2
#define IORING_UNREGISTER_FILES 3
#define IORING_REGISTER_EVENTFD 4
#define IORING_UNREGISTER_EVENTFD 5
#define IORING_REGISTER_FILES_UPDATE 6
#define IORING_REGISTER_EVENTFD_ASYNC 7
#define IORING_REGISTER_PROBE 8
#define IORING_REGISTER_PERSONALITY 9
#define IORING_UNREGISTER_PERSONALITY 10
设置了IORING_REGISTER_BUFFERS,内核会提前调用get_user_pages来获得用户态buffer虚拟地址对应的物理pages,这样在开始提交IO的时候, 内核发现如果提交的用户态buffer虚拟地址曾经被注册过,那么就免去了虚拟地址到 pages的转换,这样就节省了在提交IO时再转换pages的开销。
- void __user *arg : 参数(fd,buffer)
-
unsigned int nr_args : 参数个数
- return : <0失败(-errno)
io_uring_enter
- unsigned int fd : ring_fd
- u32 to_submit : 一次提交多少io
- u32 min_complete : 如果 flags 设置了 IORING_ENTER_GETEVENTS,并且 min_complete > 0,那么这个系统调用会同时处理 IO 收割。这个系统调用会一直 block,直到 min_complete 个 IO 已经完成。
- u32 flags :
#define IORING_ENTER_GETEVENTS (1U << 0)
#define IORING_ENTER_SQ_WAKEUP (1U << 1)
- const sigset_t __user *sig : 信号
-
size_t sigsz : 65/8
- return : <0失败(-errno)功
liburing API
liburing库实现了io_uring接口
$ wget https://github.com/axboe/liburing/archive/liburing-0.7.tar.gz
$ tar -xvf liburing-0.7.tar.gz
$ cd liburing-liburing-0.7/
$ ./configure --libdir=/usr/lib64
$ make CFLAGS='-std=gnu99'
$ sudo make install
结构
struct io_uring_sq {
unsigned *khead;
unsigned *ktail;
unsigned *kring_mask;
unsigned *kring_entries;
unsigned *kflags;
unsigned *kdropped;
unsigned *array;
struct io_uring_sqe *sqes;
unsigned sqe_head;
unsigned sqe_tail;
size_t ring_sz;
void *ring_ptr;
};
struct io_uring_cq {
unsigned *khead;
unsigned *ktail;
unsigned *kring_mask;
unsigned *kring_entries;
unsigned *kflags;
unsigned *koverflow;
struct io_uring_cqe *cqes;
size_t ring_sz;
void *ring_ptr;
};
struct io_uring {
struct io_uring_sq sq;
struct io_uring_cq cq;
unsigned flags;
int ring_fd;
};
初始化
extern int io_uring_queue_init_params(unsigned entries, struct io_uring *ring,
struct io_uring_params *p);
extern int io_uring_queue_init(unsigned entries, struct io_uring *ring,
unsigned flags);
- entries 表示队列大小
- ring 就是需要初始化的 io_uring 结构指针
- flags 是标志参数,此值会改变io_uring_params *p->flags
- io_uring_params *p 更多的设置
创建请求
获取一个sqe请求并初始化
extern struct io_uring_sqe *io_uring_get_sqe(struct io_uring *ring);
static inline void io_uring_prep_readv(struct io_uring_sqe *sqe, int fd,
const struct iovec *iovecs,
unsigned nr_vecs, off_t offset);
static inline void io_uring_prep_writev(struct io_uring_sqe *sqe, int fd,
const struct iovec *iovecs,
unsigned nr_vecs, off_t offset);
- sqe 即前面获取的 sqe 结构指针
- fd 为需要读写的文件描述符,可以是磁盘文件也可以是socket
- iovecs 为 iovec 数组,具体使用请参照 readv 和 writev
- nr_vecs 为 iovecs 数组元素个数
- offset 为文件操作的偏移量
传入用户数据
static inline void io_uring_sqe_set_data(struct io_uring_sqe *sqe, void *data);
提交请求
extern int io_uring_submit(struct io_uring *ring);
extern int io_uring_submit_and_wait(struct io_uring *ring, unsigned wait_nr);
- wait_nr 等待事件数量
获取结果
提取完成事件
static inline int io_uring_peek_cqe(struct io_uring *ring,
struct io_uring_cqe **cqe_ptr);
static inline int io_uring_wait_cqe(struct io_uring *ring,
struct io_uring_cqe **cqe_ptr);
- cqe_ptr 是输出参数,是 cqe 指针变量的地址
这两个函数,io_uring_peek_cqe 如果没有已完成的 IO 操作时,也会立即返回,cqe_ptr 被置空;而io_uring_wait_cqe 会阻塞线程,等待 IO 操作完成。
遍历宏
#define io_uring_for_each_cqe(ring, head, cqe) ...
例
assert(io_uring_submit_and_wait(&m_io_uring, 2) != -1);
struct io_uring_cqe* cqe;
uint32_t head;
uint32_t count = 0;
while (count != 2) {
io_uring_for_each_cqe(&m_io_uring, head, cqe) {
assert(cqe->res == 128);
count++;
printf("cqe res=%d data=%lld\n", cqe->res, cqe->user_data);
}
assert(count <= 2);
io_uring_cq_advance(&m_io_uring, count);
}
获取数据
static inline void *io_uring_cqe_get_data(const struct io_uring_cqe *cqe);
清理完成事件
static inline void io_uring_cqe_seen(struct io_uring *ring,
struct io_uring_cqe *cqe)
{
if (cqe)
io_uring_cq_advance(ring, 1);
}
释放
extern void io_uring_queue_exit(struct io_uring *ring);
例子
| 文件 | 说明 |
|---|---|
| test/read-write.c | |
| test/send_recv.c |