Jetson Xavier NX / PyTorch 安装记录

版本比对
| AliYun Server | Jetson Xavier NX | |
|---|---|---|
| pytorch | 1.8.1 | 1.8.1 |
| torchvision | 0.9.1 | 0.9.0a0+8fb5838 |
| torchaudio | 0.8.1 | |
| cudatoolkit | 10.2 | |
| fastapi | 0.65.2 | 0.65.2 |
| uvicorn[standard] | 0.14.0 | 0.14.0 |
| python-multipart | 0.0.5 | 0.0.5 |
| loguru | 0.5.3 | 0.5.3 |
| numpy | 1.20.2 | 1.20.2 |
| pandas | 1.2.5 | 1.2.5 |
| matplotlib | 3.4.2 | 3.4.2 |
| scipy | 1.7.0 | 1.7.0 |
| Pillow | 8.2.0 | 8.2.0 |
| tqdm | 4.61.1 | 4.61.1 |
| opencv-python | 4.5.2.54 | 4.5.2.54 |
| esdk-obs-python | 3.20.11 | 3.20.11 |
| oss2 | 2.14.0 | 2.14.0 |
附录
https://developer.nvidia.com/embedded/linux-tegra
Jetson Xavier NX 固件
dmesg | tail | awk '$3 == "sd" {print}'
unzip -p ~/Downloads/jetson-nx-jp46-sd-card-image.zip | sudo /bin/dd of=/dev/sd<x> bs=1M status=progress
sudo eject /dev/sd<x>
$ cat /etc/os-release
NAME="Ubuntu"
VERSION="18.04.5 LTS (Bionic Beaver)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 18.04.5 LTS"
VERSION_ID="18.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=bionic
UBUNTU_CODENAME=bionic
$ uname -a
Linux aipos-desktop 4.9.253-tegra #1 SMP PREEMPT Mon Jul 26 12:19:28 PDT 2021 aarch64 aarch64 aarch64 GNU/Linux
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 15G 13G 1.3G 91% /
devtmpfs 3.5G 0 3.5G 0% /dev
tmpfs 3.8G 40K 3.8G 1% /dev/shm
tmpfs 3.8G 23M 3.8G 1% /run
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 3.8G 0 3.8G 0% /sys/fs/cgroup
tmpfs 777M 4.0K 777M 1% /run/user/0
tmpfs 777M 20K 777M 1% /run/user/120
tmpfs 777M 148K 777M 1% /run/user/1000
$ cat /usr/local/cuda/version.txt
CUDA Version 10.2.300
依赖与设置
sudo apt update
sudo apt install -y tzdata ffmpeg libsm6 libxext6
# 设置时区
export TZ=Asia/Shanghai
ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
关于eMMC烧写系统:
Jetson Xavier NX (当前市场上拿到的只有emmc版本)有以下对应:
Module Part Number: Jetson Xavier NX P3668-0001
Value of $(BOARD): p3449-0000+p3668-0001-qspi-emmc
./flash.sh p3449-0000+p3668-0001-qspi-emmc mmcblk0p1
安装PyTorch / vision
wget https://nvidia.box.com/shared/static/p57jwntv436lfrd78inwl7iml6p13fzh.whl -O torch-1.8.0-cp36-cp36m-linux_aarch64.whl
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
pip3 install Cython
pip3 install numpy torch-1.8.0-cp36-cp36m-linux_aarch64.whl
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev
$ git clone --branch v0.9.0 https://github.com/pytorch/vision torchvision
$ cd torchvision
$ export BUILD_VERSION=0.9.0
$ python3 setup.py install --user
$ cd ../
$ pip install 'pillow<7'
requirements.txt
fastapi==0.65.2
uvicorn[standard]==0.14.0
python-multipart==0.0.5
loguru==0.5.3
#numpy==1.20.2
pandas==1.2.5
matplotlib==3.4.2
scipy==1.7.0
Pillow==8.2.0
tqdm==4.61.1
opencv-python==4.5.2.54
esdk-obs-python==3.20.11
oss2==2.14.0
安装依赖
python -m pip install --upgrade pip
pip3 download -d ./local_wheels -r requirements.txt
pip3 install ./local_wheels/*.whl
# or --------------------------------------------
pip3 install -r ./requirements.txt
校验
import torch
import torchvision
print('Torch version: ' + str(torch.__version__))
print('Vision version: ' + str(torchvision.__version__))
print('CUDA available: ' + str(torch.cuda.is_available()))
print('cuDNN version: ' + str(torch.backends.cudnn.version()))
a = torch.cuda.FloatTensor(2).zero_()
print('Tensor a = ' + str(a))
b = torch.randn(2).cuda()
print('Tensor b = ' + str(b))
c = a + b
print('Tensor c = ' + str(c))
编译
实际安装记录
安装1.8.0成功
NVIDIA论坛版本
sudo apt update
sudo apt-get install curl vim
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
pip3 install Cython
pip3 install numpy torch-1.8.0-cp36-cp36m-linux_aarch64.whl -i https://mirrors.aliyun.com/pypi/simple/
$ python3 check.py
Torch version: 1.8.0
CUDA available: True
cuDNN version: 8201
Tensor a = tensor([0., 0.], device='cuda:0')
Tensor b = tensor([ 0.4454, -0.4111], device='cuda:0')
Tensor c = tensor([ 0.4454, -0.4111], device='cuda:0')
# 卸载回退
pip3 uninstall Cython numpy typing_extensions dataclasses
pip3 uninstall torch-1.8.0-cp36-cp36m-linux_aarch64.whl
安装1.8.1失败
继续上一节
PyTorch官方版本
sudo apt-get install python3.8 python3.8-dev
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev
cd /usr/bin
sudo rm python3
sudo ln -s python3.8 python3
pip3 install --upgrade pip
python3 -m pip uninstall setuptools
python3 -m pip install setuptools
python3 -m pip uninstall Cython
python3 -m pip install Cython
vi .bashrc
export PATH=$PATH:/home/aipos/.local/bin
source .bashrc
python3 -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
git clone https://github.com/protocolbuffers/protobuf.git
cd protobuf
git checkout v3.3.2
git submodule update --init --recursive
./autogen.sh
./configure
make -j5
# make check -j5
sudo make install
sudo ldconfig
python3 -m pip install torch==1.8.1 torchvision==0.9.1
$ python3 ./check.py
Torch version: 1.8.1
CUDA available: False
cuDNN version: None
Traceback (most recent call last):
File "./check.py", line 9, in <module>
a = torch.cuda.FloatTensor(2).zero_()
TypeError: type torch.cuda.FloatTensor not available. Torch not compiled with CUDA enabled.
# 卸载回退
python3 -m pip uninstall torch==1.8.1 torchvision==0.9.1
编译安装1.8.1成功
git clone --recursive --branch v1.8.1 http://github.com/pytorch/pytorch
cd pytorch
# path 打补丁
sudo apt-get install python3-pip cmake libopenblas-dev
python3 -m pip install -r requirements.txt
python3 -m pip install scikit-build
python3 -m pip install ninja
# https://developer.nvidia.com/how-to-cuda-python
# python3 -m pip install cudatoolkit==10.2
export USE_NCCL=0
export USE_DISTRIBUTED=0
export USE_QNNPACK=0
export USE_PYTORCH_QNNPACK=0
export TORCH_CUDA_ARCH_LIST="5.3;6.2;7.2"
export PYTORCH_BUILD_VERSION=1.8.1
export PYTORCH_BUILD_NUMBER=1
export MAX_JOBS=4
python3 setup.py bdist_wheel
python3 -m pip install dist/torch-1.8.1-cp38-cp38-linux_aarch64.whl
git clone https://github.com/pytorch/vision
cd vision
git checkout v0.9.1
python3 setup.py bdist_wheel
python3 -m pip install dist/torchvision-0.9.0a0+8fb5838-cp38-cp38-linux_aarch64.whl
git clone https://github.com/pytorch/audio
cd audio
git checkout v0.8.1
python3 setup.py bdist_wheel # 编译失败,暂时放弃
$ python3 check.py
Torch version: 1.8.1
Vision version: 0.9.0a0+8fb5838
CUDA available: True
cuDNN version: 8201
Tensor a = tensor([0., 0.], device='cuda:0')
Tensor b = tensor([-0.8374, -0.4737], device='cuda:0')
Tensor c = tensor([-0.8374, -0.4737], device='cuda:0')
diff --git a/aten/src/ATen/cpu/vec256/vec256_float_neon.h b/aten/src/ATen/cpu/vec256/vec256_float_neon.h
index 58a4afac17..af5ed65cc8 100644
--- a/aten/src/ATen/cpu/vec256/vec256_float_neon.h
+++ b/aten/src/ATen/cpu/vec256/vec256_float_neon.h
@@ -26,6 +26,9 @@ namespace {
// Most likely we will do aarch32 support with inline asm.
#if defined(__aarch64__)
+// See https://github.com/pytorch/pytorch/issues/47098
+#if defined(__clang__) || (__GNUC__ > 8 || (__GNUC__ == 8 && __GNUC_MINOR__ > 3))
+
#ifdef __BIG_ENDIAN__
#error "Big endian is not supported."
#endif
@@ -694,6 +697,7 @@ Vec256<float> inline fmadd(const Vec256<float>& a, const Vec256<float>& b, const
return Vec256<float>(r0, r1);
}
+#endif /* defined(__clang__) || (__GNUC__ > 8 || (__GNUC__ == 8 && __GNUC_MINOR__ > 3)) */
#endif /* defined(aarch64) */
}}}
diff --git a/aten/src/ATen/cuda/CUDAContext.cpp b/aten/src/ATen/cuda/CUDAContext.cpp
index 1751128f1a..03e74f5ac2 100644
--- a/aten/src/ATen/cuda/CUDAContext.cpp
+++ b/aten/src/ATen/cuda/CUDAContext.cpp
@@ -24,6 +24,8 @@ void initCUDAContextVectors() {
void initDeviceProperty(DeviceIndex device_index) {
cudaDeviceProp device_prop;
AT_CUDA_CHECK(cudaGetDeviceProperties(&device_prop, device_index));
+ // patch for "too many resources requested for launch"
+ device_prop.maxThreadsPerBlock = device_prop.maxThreadsPerBlock / 2;
device_properties[device_index] = device_prop;
}
diff --git a/aten/src/ATen/cuda/detail/KernelUtils.h b/aten/src/ATen/cuda/detail/KernelUtils.h
index 45056ab996..81a0246ceb 100644
--- a/aten/src/ATen/cuda/detail/KernelUtils.h
+++ b/aten/src/ATen/cuda/detail/KernelUtils.h
@@ -22,7 +22,10 @@ namespace at { namespace cuda { namespace detail {
// Use 1024 threads per block, which requires cuda sm_2x or above
-constexpr int CUDA_NUM_THREADS = 1024;
+//constexpr int CUDA_NUM_THREADS = 1024;
+
+// patch for "too many resources requested for launch"
+constexpr int CUDA_NUM_THREADS = 512;
// CUDA: number of blocks for threads.
inline int GET_BLOCKS(const int64_t N) {
diff --git a/aten/src/ATen/native/cpu/BinaryOpsKernel.cpp b/aten/src/ATen/native/cpu/BinaryOpsKernel.cpp
index 4e9c799986..12c1453073 100644
--- a/aten/src/ATen/native/cpu/BinaryOpsKernel.cpp
+++ b/aten/src/ATen/native/cpu/BinaryOpsKernel.cpp
@@ -24,7 +24,13 @@ using namespace vec256;
// copysign faster for the half-precision types
template<typename T>
T copysign(T a, T b) {
+#if (!defined(__aarch64__)) || defined(__clang__) || (__GNUC__ > 8)
+ // std::copysign gets ICE/Segfaults with gcc 7/8 on arm64
+ // (e.g. Jetson), see PyTorch PR #51834
return std::copysign(a, b);
+#else
+ return std::signbit(b) ? -std::abs(a) : std::abs(a);
+#endif
}
// Implement copysign for half precision floats using bit ops
@@ -149,6 +155,18 @@ void div_trunc_kernel(TensorIterator& iter) {
}
}
+// this is a function because MSVC does not like us to use #if inside AT_DISPATC
+template <typename scalar_t>
+static inline scalar_t signed_zero(scalar_t sign) {
+#if (!defined(__aarch64__)) || defined(__clang__) || (__GNUC__ > 8)
+ // std::copysign gets ICE/Segfaults with gcc 7/8 on arm64
+ // (e.g. Jetson), see PyTorch PR #51834
+ return std::copysign(scalar_t(0), sign);
+#else
+ return std::signbit(sign) ? -scalar_t(0) : scalar_t(0);
+#endif
+}
+
// NOTE: [Floor Division in Python]
// Python's __floordiv__ operator is more complicated than just floor(a / b).
// It aims to maintain the property: a == (a // b) * b + remainder(a, b)
@@ -201,7 +219,7 @@ void div_floor_kernel(TensorIterator& iter) {
floordiv += scalar_t(1.0);
}
} else {
- floordiv = copysign(scalar_t(0), a / b);
+ floordiv = signed_zero(a / b);
}
return floordiv;
});
diff --git a/aten/src/ATen/native/cuda/BinaryMulDivKernel.cu b/aten/src/ATen/native/cuda/BinaryMulDivKernel.cu
index e3ac2665a4..2d8d302d35 100644
--- a/aten/src/ATen/native/cuda/BinaryMulDivKernel.cu
+++ b/aten/src/ATen/native/cuda/BinaryMulDivKernel.cu
@@ -5,6 +5,7 @@
#include <ATen/native/TensorIterator.h>
#include <ATen/native/BinaryOps.h>
#include <c10/cuda/CUDAGuard.h>
+#include <c10/cuda/CUDAMathCompat.h>
// NOTE: CUDA on Windows requires that the enclosing function
// of a __device__ lambda not have internal linkage.
@@ -139,7 +140,9 @@ void div_floor_kernel_cuda(TensorIterator& iter) {
floordiv += scalar_t(1.0);
}
} else {
- floordiv = std::copysign(scalar_t(0), a * inv_b);
+ // std::copysign gets ICE/Segfaults with gcc 7/8 on arm64
+ // (e.g. Jetson), see PyTorch PR #51834
+ floordiv = c10::cuda::compat::copysign(scalar_t(0), a * inv_b);
}
return floordiv;
});
@@ -160,7 +163,9 @@ void div_floor_kernel_cuda(TensorIterator& iter) {
floordiv += scalar_t(1.0);
}
} else {
- floordiv = std::copysign(scalar_t(0), a / b);
+ // std::copysign gets ICE/Segfaults with gcc 7/8 on arm64
+ // (e.g. Jetson), see PyTorch PR #51834
+ floordiv = c10::cuda::compat::copysign(scalar_t(0), a / b);
}
return floordiv;
});
diff --git a/aten/src/THCUNN/common.h b/aten/src/THCUNN/common.h
index 69b7f3a4d3..54455ab4b0 100644
--- a/aten/src/THCUNN/common.h
+++ b/aten/src/THCUNN/common.h
@@ -5,7 +5,10 @@
"Some of weight/gradient/input tensors are located on different GPUs. Please move them to a single one.")
// Use 1024 threads per block, which requires cuda sm_2x or above
-const int CUDA_NUM_THREADS = 1024;
+//const int CUDA_NUM_THREADS = 1024;
+
+// patch for "too many resources requested for launch"
+constexpr int CUDA_NUM_THREADS = 512;
// CUDA: number of blocks for threads.
inline int GET_BLOCKS(const int64_t N)
diff --git a/c10/cuda/CUDAMathCompat.h b/c10/cuda/CUDAMathCompat.h
index 1fb0c3ec29..a4c6655859 100644
--- a/c10/cuda/CUDAMathCompat.h
+++ b/c10/cuda/CUDAMathCompat.h
@@ -42,11 +42,80 @@ __MATH_FUNCTIONS_DECL__ double ceil(double x) {
return ::ceil(x);
}
+__MATH_FUNCTIONS_DECL__ float fp32_from_bits(uint32_t w) {
+#if defined(__OPENCL_VERSION__)
+ return as_float(w);
+#elif defined(__CUDA_ARCH__)
+ return __uint_as_float((unsigned int)w);
+#elif defined(__INTEL_COMPILER)
+ return _castu32_f32(w);
+#else
+ union {
+ uint32_t as_bits;
+ float as_value;
+ } fp32 = {w};
+ return fp32.as_value;
+#endif
+}
+
+__MATH_FUNCTIONS_DECL__ uint32_t fp32_to_bits(float f) {
+#if defined(__OPENCL_VERSION__)
+ return as_uint(f);
+#elif defined(__CUDA_ARCH__)
+ return (uint32_t)__float_as_uint(f);
+#elif defined(__INTEL_COMPILER)
+ return _castf32_u32(f);
+#else
+ union {
+ float as_value;
+ uint32_t as_bits;
+ } fp32 = {f};
+ return fp32.as_bits;
+#endif
+}
+
+__MATH_FUNCTIONS_DECL__ double fp64_from_bits(uint64_t w) {
+#if defined(__CUDA_ARCH__)
+ return __longlong_as_double(w);
+#else
+ union {
+ uint64_t as_bits;
+ double as_value;
+ } fp64 = {w};
+ return fp64.as_value;
+#endif
+}
+
+__MATH_FUNCTIONS_DECL__ uint64_t fp64_to_bits(double f) {
+#if defined(__CUDA_ARCH__)
+ return __double_as_longlong(f);
+#else
+ union {
+ double as_value;
+ int64_t as_bits;
+ } fp64 = {f};
+ return fp64.as_bits;
+#endif
+}
+
__MATH_FUNCTIONS_DECL__ float copysign(float x, float y) {
- return ::copysignf(x, y);
+#if (!defined(__aarch64__)) || defined(__clang__) || (__GNUC__ > 8)
+ // std::copysign gets ICE/Segfaults with gcc 7/8 on arm64
+ // (e.g. Jetson), see PyTorch PR #51834
+ return ::copysignf(x, y);
+#else
+ return fp32_from_bits(
+ (fp32_to_bits(x) & 0x7fffffffu) | (fp32_to_bits(y) & 0x80000000u));
+#endif
}
__MATH_FUNCTIONS_DECL__ double copysign(double x, double y) {
- return ::copysign(x, y);
+#if (!defined(__aarch64__)) || defined(__clang__) || (__GNUC__ > 8)
+ return ::copysign(x, y);
+#else
+ return fp64_from_bits(
+ (fp64_to_bits(x) & 0x7fffffffffffffffull) |
+ (fp64_to_bits(y) & 0x8000000000000000ull));
+#endif
}
__MATH_FUNCTIONS_DECL__ float floor(float x) {
其它研究备忘
cat /etc/apt/sources.list.d/nvidia-l4t-apt-source.list
deb https://repo.download.nvidia.com/jetson/common r32.6 main
deb https://repo.download.nvidia.com/jetson/t194 r32.6 main
测试与监控
不支持nvidia-smi
sudo tegrastats | grep GR3D # GR3D=GPU
sudo -H python3 pip install jetson-stats
sudo jtop
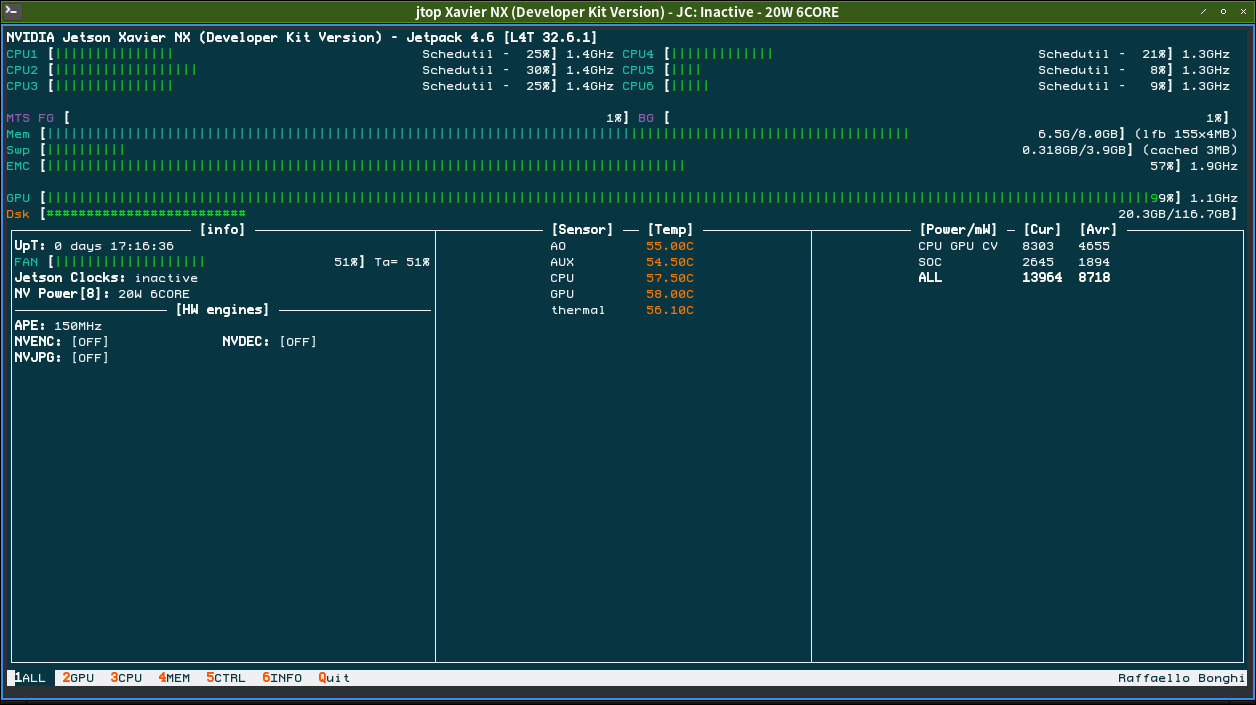
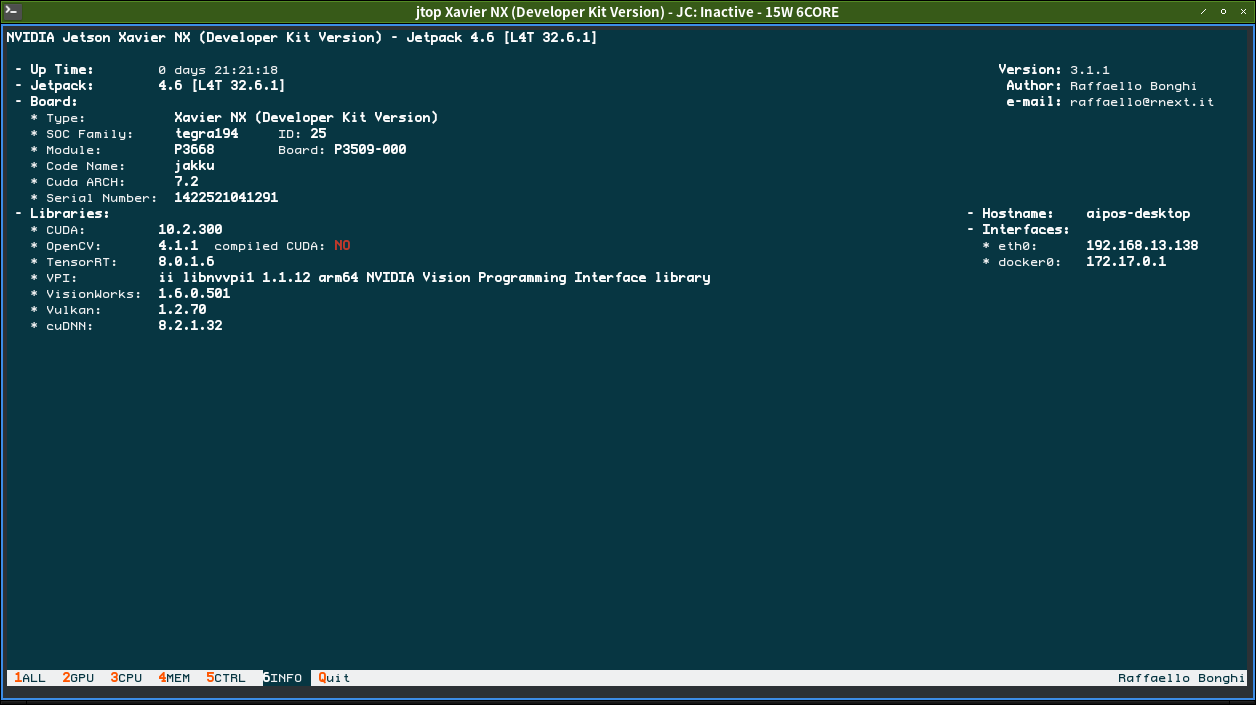
功率调整
调到20W后GPU就不发生变频
# 15W 6CORE
sudo nvpmodel -m 2
# 20W 6CORE
# sudo nvpmodel -m 8
sudo jetson_clocks